How Does An AI Chatbot Work? NLP, GenAI, And Training Data
Shlok Sobti

How Does An AI Chatbot Work? NLP, GenAI, And Training Data
You ask a chatbot a question, and it replies with something that actually makes sense. Sometimes it even sounds human. But how does an AI chatbot work under the hood? What's happening between your typed message and that eerily accurate response? These aren't scripted FAQ bots from 2015, modern AI chatbots process language, generate original responses, and learn from massive datasets to hold conversations that feel natural.
At Invsify, we built our Conversational RM AI on these exact technologies to give you 24/7 multilingual financial guidance, from investment queries to portfolio insights. So understanding how chatbots work isn't just a tech curiosity for us; it's the foundation of what we offer as a SEBI Registered Investment Advisor.
This article breaks down the core technologies that power AI chatbots: Natural Language Processing (NLP), Generative AI (GenAI), and the training data that ties it all together. You'll learn how a chatbot interprets your words, decides what you mean, and constructs a relevant reply, step by step, without the jargon overload. Whether you're a developer, a curious investor, or someone evaluating AI tools for personal finance, this guide gives you the clarity you need.
Why AI chatbots matter in real-world apps
AI chatbots are no longer a novelty feature bolted onto a company's website. Today, they handle millions of customer interactions daily across banking, healthcare, retail, and education. The shift happened because modern chatbots can actually understand context, remember previous messages within a session, and respond with relevant, personalized answers rather than canned scripts. That transformation from simple button-click bots to genuinely conversational tools changed how businesses think about customer engagement entirely. Companies that once needed large call centers to answer repetitive queries now rely on AI assistants to cover that volume instantly, at any hour.
From rule-based bots to intelligent assistants
The earliest chatbots operated on decision-tree logic: you pick option 1, it gives you a preset response. These rule-based systems were rigid. If you typed something outside their expected input, they failed immediately. Modern AI chatbots work differently because they don't rely on fixed rules. They use language models trained on enormous text datasets to interpret what you mean, even when you phrase things in an unusual or incomplete way. Understanding how does an AI chatbot work today means recognizing that the intelligence comes from statistical patterns learned from billions of examples, not from hand-coded if-then rules written by a programmer.
The jump from rule-based bots to AI-driven assistants mirrors the jump from a paper map to a GPS that reroutes dynamically in real time.
Real-world use cases that show the shift
You can see AI chatbots doing meaningful work across sectors that directly affect your daily life. Here are some of the most active deployment areas right now:
E-commerce: Chatbots help you track orders, process returns, and recommend products based on your browsing history.
Healthcare: They assist patients in scheduling appointments, understanding symptoms, and accessing medical records without calling a clinic.
Banking: Chatbots handle balance inquiries, flag suspicious transactions, and clarify loan eligibility in seconds.
Education: They tutor students by answering questions in real time and adjusting explanations to match the learner's current level.
Investment advisory: Chatbots deliver personalized portfolio insights, answer market questions, and walk you through financial decisions without requiring you to wait for business hours.
Each of these use cases shares a common thread: the chatbot replaces a repetitive, high-volume task that would otherwise require a human agent, while still delivering a response that feels accurate and specific to your situation. The result is faster resolution and lower friction for the user, with fewer handoffs and hold times.
Why financial services benefit the most
Financial queries are often time-sensitive and highly personal. You might want to know if your SIP is on track at 11 PM on a Sunday, or you might need to understand the tax implications of switching mutual funds before a deadline. A human advisor isn't always available at those moments. An AI chatbot, by contrast, operates around the clock without fatigue, drawing from your actual portfolio data and current market context to give you a relevant answer immediately.
For SEBI Registered Investment Advisors like Invsify, this matters beyond convenience. It means conflict-free, data-backed guidance reaches every user the moment they need it, not just during office hours. The chatbot earns no commission on the products it mentions. It has no incentive to favor one fund over another. That structural transparency, combined with AI's ability to process your complete financial picture instantly, makes chatbots a genuinely useful tool for wealth management, not just a cost-cutting shortcut for service teams.
The building blocks inside an AI chatbot
Every AI chatbot you interact with relies on a layered set of components working in sequence. None of these layers operates alone. To understand how does an AI chatbot work, you need to know what each layer does and how it passes information to the next one. The three core building blocks are Natural Language Processing, a Large Language Model, and a context window that ties each exchange together.
Natural Language Processing: how the chatbot reads your input
Natural Language Processing, or NLP, is the layer that converts your raw text into structured data the model can actually work with. When you type a message, the chatbot runs it through several sub-processes that strip away ambiguity and identify what you actually mean. NLP also handles spelling variations, slang, and incomplete sentences, so you don't need to phrase your question perfectly to get a useful response.
The key NLP sub-processes running on your input include:
Tokenization: splits your sentence into smaller word units the model can read
Intent recognition: identifies the core goal behind your message
Entity extraction: picks out specific names, dates, or figures you mention
Sentiment analysis: detects tone, especially useful in customer-facing applications
The smarter the NLP layer, the less you have to "talk like a robot" to get a precise response.
Large Language Models and the context window
The Large Language Model, or LLM, is the core engine that generates the actual reply. It's a neural network trained on enormous text datasets, and it predicts the most statistically likely next token, building your response word by word. Models built on the transformer architecture weigh the relevance of every word in your input relative to every other word before generating output, which is why they handle nuanced follow-up questions instead of treating each message as a disconnected prompt.
Context management works alongside the LLM to give the chatbot short-term memory within your session. When you ask a follow-up question, the model pulls from the conversation history inside the context window to understand what "it" or "that" refers to in your message. Without this mechanism, every new message would reset the conversation, making the chatbot useless for multi-step tasks like walking through a financial plan or breaking down a complex portfolio decision.
What happens after you hit send, step by step
The moment you press send, a sequence of operations fires in milliseconds behind the interface. Most users never see this pipeline, but understanding it answers the core question of how does an AI chatbot work in practice. Each step transforms your raw text into a structured, context-aware response, and every step depends on the one before it completing successfully.
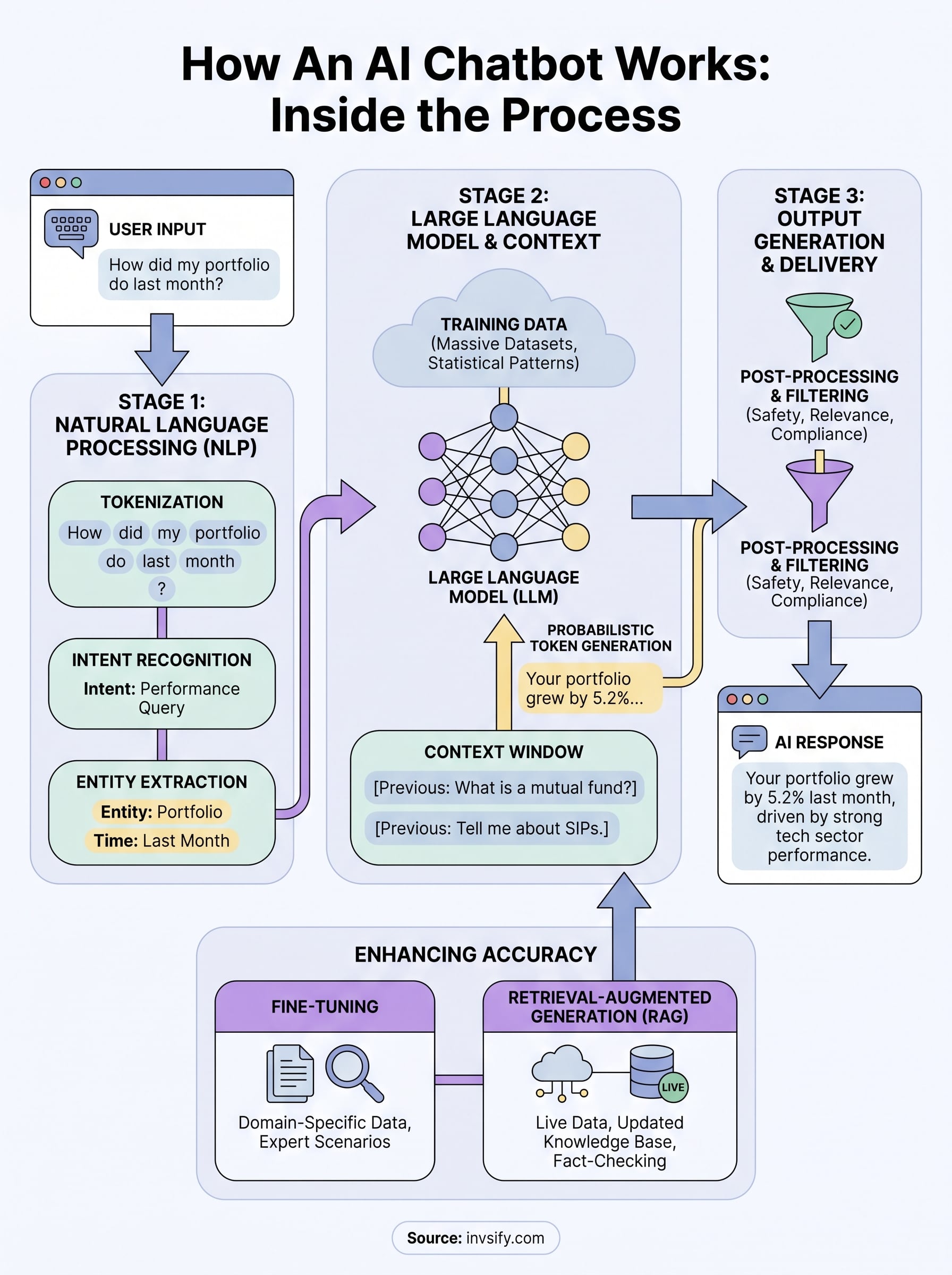
Step 1: Input processing and intent resolution
Your message first passes through the NLP preprocessing layer, which cleans and structures the text before anything else touches it. The system tokenizes your input, breaks it into smaller units, and runs it through intent recognition to determine what you are actually asking. If you write "how much did my portfolio grow last month," the model extracts the intent (performance query), the entity (portfolio), and the time reference (last month) as distinct data points rather than reading the sentence as a single unstructured string.
The cleaner your input data, the more accurately the model resolves your intent, but a good chatbot handles messy input without breaking.
Context from your previous messages also loads into the working memory at this stage. If you asked about your SIP returns two exchanges ago, the model carries that information forward so your follow-up question reads as a continuation, not a new isolated request.
Step 2: Model inference and token generation
The processed input feeds directly into the Large Language Model, which runs inference to produce a response. The transformer architecture scans every token in your input and the conversation history simultaneously, weighing relationships between words to determine what output makes the most sense. Then it generates your reply one token at a time, with each new token influenced by everything that came before it in that sequence.
This generative process is probabilistic, not deterministic. The model selects each token based on a probability distribution shaped by its training, which is why two slightly different phrasings of the same question can sometimes yield noticeably different answers.
Step 3: Output filtering and delivery
Before the response reaches your screen, a post-processing layer reviews the generated text for safety, relevance, and format. In financial applications like Invsify's Conversational RM AI, this layer also checks that the output aligns with regulatory standards before delivery. The final, filtered text then renders in your chat interface, typically within one to three seconds of you pressing send.
Training data, tuning, and grounding for accuracy
A chatbot's responses are only as reliable as the data it was trained on. Understanding this layer of how does an AI chatbot work helps you evaluate why some chatbots give sharp, accurate answers while others produce confident-sounding nonsense. The base model learns language patterns from vast text corpora pulled from books, websites, and other written sources, but raw training alone rarely produces a chatbot you can trust in a specialized domain like personal finance.
How training data shapes a chatbot's knowledge
The training corpus defines the boundaries of what the model knows. A model trained primarily on general web text will handle everyday conversations but may struggle with precise, domain-specific queries involving tax rules, investment regulations, or portfolio math. Domain-specific training data, curated from verified financial documents, regulatory guidelines, and expert commentary, closes that gap by giving the model accurate reference points to draw from when generating responses.
The quality of training data matters more than the volume. A smaller, clean dataset outperforms a massive but noisy one when accuracy is the goal.
Training data also carries a cutoff date, which means the base model has no knowledge of events that occurred after it was trained. Any chatbot operating in a fast-moving domain, like markets or tax law, needs additional mechanisms layered on top of base training to stay current and avoid outdated answers.
Fine-tuning and retrieval-augmented generation
Fine-tuning takes a pre-trained base model and continues training it on a narrower, curated dataset specific to your use case. For a financial advisory chatbot, this means exposing the model to actual investment scenarios, regulatory language, and domain-specific question-and-answer pairs so it learns to respond with appropriate precision rather than general approximations. Fine-tuning shapes the model's tone, depth, and accuracy within the domain you care about.

Retrieval-Augmented Generation, or RAG, solves the freshness problem that fine-tuning alone cannot fix. Instead of relying purely on memorized training data, a RAG system pulls live or updated information from a connected knowledge base at the moment you ask a question. At Invsify, this approach means the chatbot can reference your actual portfolio data and current market context to give you answers grounded in your real financial situation rather than generic assumptions.
Limits, risks, and how to evaluate quality
Knowing how does an AI chatbot work helps you use it well, but knowing where it breaks down keeps you from trusting it blindly. Even sophisticated models produce wrong answers with the same confident tone they use for correct ones. This pattern is called hallucination: the model generates a statistically plausible response that has no factual basis. In high-stakes domains like personal finance, a hallucinated answer about tax rules or investment regulations can cause real harm, which is why you should never treat any AI output as a final authority without verifying the underlying source.
Where chatbots commonly fail
Chatbots fail most visibly in three areas: factual accuracy, domain boundaries, and session memory limits. When a question falls outside the model's training data or exceeds the context window, it fills the gap with plausible-sounding text rather than admitting uncertainty. This is particularly risky when you ask about recent regulatory changes or current market events that occurred after the model's training cutoff date. Retrieval-augmented systems reduce this risk, but they still depend on the quality and freshness of their connected knowledge base.
Here are the most common failure modes to watch for:
Hallucination: the chatbot states false information confidently
Outdated knowledge: responses based on data that predates recent changes
Context drop: the chatbot loses track of earlier parts of your conversation
Overgeneralization: the response applies a general rule to a situation that requires specific advice
How to evaluate a chatbot before trusting it
Before relying on a chatbot for decisions that affect your money, check whether it cites sources or references the underlying data it draws from. A quality financial chatbot should tell you where its answer originates, whether from your actual portfolio data, a regulatory document, or a live market feed. Vague, unsourced responses signal that the model is generating from pattern rather than from verified, grounded information.
A chatbot that admits it does not know something is more trustworthy than one that always produces an answer.
Test the chatbot with a question you already know the answer to. If it gets that wrong or hedges excessively, apply the same skepticism to its other outputs. Regulatory accountability adds meaningful protection: a chatbot built by a SEBI Registered Investment Advisor operates under defined standards and oversight that a generic AI tool does not, which significantly reduces the risk of misleading advice reaching you.
Next steps
Now you know how does an AI chatbot work: from NLP parsing your input, to an LLM generating a token-by-token response, to retrieval-augmented grounding that keeps answers accurate and current. That full pipeline runs in seconds every time you send a message, and the quality of each layer directly determines the quality of the advice you receive. A chatbot built on verified data, domain-specific fine-tuning, and regulatory accountability gives you fundamentally different results than a general-purpose tool that has no stake in getting your financial situation right.
Invsify's Conversational RM AI applies exactly this architecture to your personal wealth management: 24/7 multilingual guidance, portfolio-grounded answers, and zero commission incentives distorting the advice. You get responses built on your actual financial picture, not generic assumptions pulled from the open web. If you want to see what conflict-free, AI-powered financial advisory looks like in practice, start your free account with Invsify today.
